

Last week Google decided to share some information about the utility and performance of its home-grown Tensor Processing Unit (TPU) accelerator chip. Google designed this AI accelerator after foreseeing difficulties in using off-the-shelf solutions from the likes of Intel and Nvidia. It developed the TPU remarkably quickly to cater for the boom in voice and image search, and translation services, and more. The TPU was in operation in 2015, just two or three years after development started.

Nvidia Tesla K80
Nvidia likes to promote itself as a company at the cutting edge of AI, plus the associated data centre and deep learning technologies. So reading about Google's TPU benchmarks and comparisons in performance to contemporary older Nvidia accelerators like the Tesla K80 might have spoiled Nvidia CEO Jensen Huang's morning coffee.
Yesterday Jensen Huang wrote a response of sorts via the Nvidia Blog. In a post entitled 'AI drives the rise of accelerated computing in data centres', Huang agreed with Google's assertion that practical AI, for voice and image recognition, translation, and more on the internet today, requires accelerated computing. Accelerators power deep learning which helps create these AIs, and is also being used outside of web tech in areas such as diagnosing cancer and teaching autonomous cars to drive.

Nvidia Tesla P40
Turning to the Google TPU benchmark results, Huang highlights the fact that while Nvidia's Kepler-generation GPU, architected in 2009, "helped awaken the world to the possibility of using GPU-accelerated computing in deep learning, it was never specifically optimized for that task". Since that time Nvidia has progressed though Maxwell, and now Pascal architectures implementing "many architecture advances specifically for deep learning".
In headline performance terms the "Pascal-based Tesla P40 Inferencing Accelerator delivers 26x its (Kepler's) deep-learning inferencing performance, far outstripping Moore's law," says Nvidia CEO Huang. Google's TPU data said that its chip offered 13x the inferencing performance of the Tesla K80 - by simple maths that makes the Nvidia Tesla P40 is twice as fast as the Google TPU… Nvidia created a comparison table with more performance metrics included, as below:
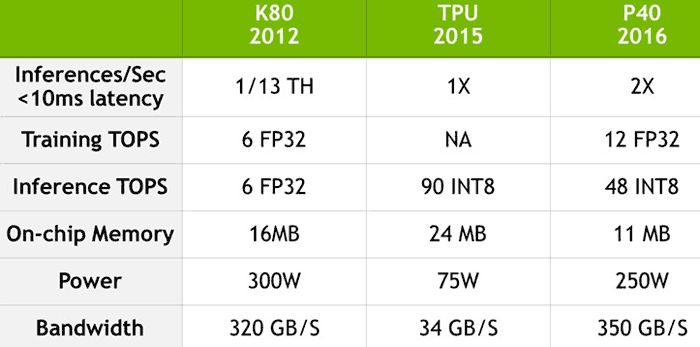
The 'NA' in the above table is there as the Google TPU doesn't run training tasks. We can see great progress in the change from the Kepler to Pascal Tesla accelerators. However Google's custom ASIC still gets its work done at about double the speed, in integer teraops, with remarkable power efficiency - a major consideration in its huge data centres.
Nvidia watches rival firms' benchmark comparisons very closely for 'fairness', further evidence comes from back in August last year when it took Intel to task for comparing its new Xeon Phi coprocessor cards with much older Nvidia Tesla K20X (Kepler) accelerators.



