

Faster, More Efficient Memory - GDDR6
There's little point in beefing-up the core efficiency and L1 and L2 caches if overall performance, particularly at higher resolutions, is compromised by memory. There was thought that Nvidia would continue to adopt new HBM2 memory for Turing but the economic reality is that it remains too expensive to implement across a wide range of consumer cards.
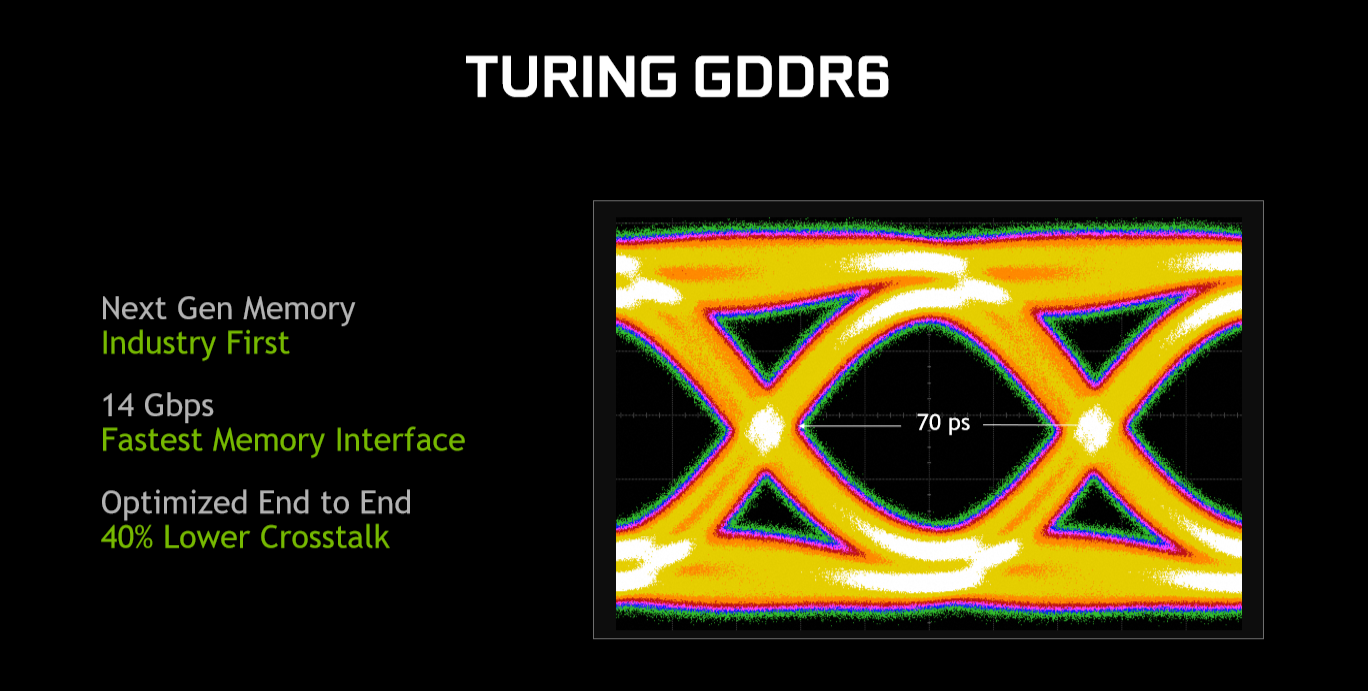
Instead, Nvidia has worked with industry partners to bring GDDR6 to the table. Specifically, it says that 'GDDR6 memory interface circuits in Turing GPUs have been completely redesigned for speed, power efficiency, and noise reduction. This new interface design comes with many new circuit and signal training improvements that minimise noise and variations due to process, temperature, and supply voltage.'
There's significantly less crosstalk, too, and Nvidia further reckons there's a decent power-efficiency improvement over the GDDR5X used in Pascal, to the tune of 20 per cent, though it is unclear whether this is at an ISO speed. GTX 1080 Ti tops out at 11Gbps, so knowing that the maximum bus width is the same 384-bits on both designs, Turing offers 27 per cent more nominal bandwidth.
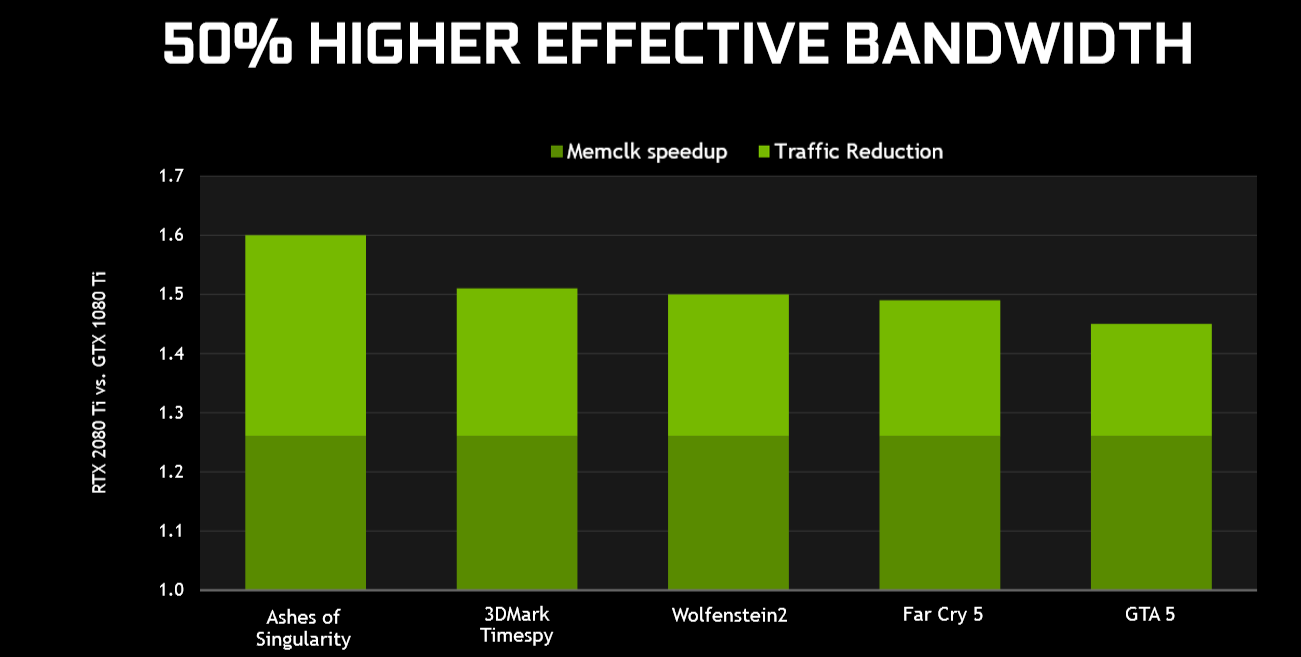
The actual, real-world, effective bandwidth improvement is closer to 50 per cent because of, one would assume, the help that larger caches and improved memory-compression algorithms give in reducing the number of off-chip memory accesses to the frame buffer.
{kind=link}
What Nvidia is saying, therefore, is that on a like-for-like basis Turing's shaders do 50 per cent more work and the GPUs have 50 per cent more bandwidth to play with.
Causing the odd eyebrow to be raised is the lack of commensurate improvement or enlargement of the backend ROPS. You'd think having all this extra shading power on tap would require more than 96 ROPS, but there you go. Maybe a technology known as DLSS, discussed deeper into the article, is Nvidia's ROP get-out clause.