

Architecture Recap
Navi = GCN+RDNA
The first interpretation of the Navi GPU is interesting because it uses established GCN technology and some new RDNA goodness - the improvements, if you will - to produce a somewhat hybrid-architecture GPU.
AMD understands that GCN remains excellent for math-heavy problems where its massive TFLOPS throughput and parallelism comes into play. The Radeon Vega 64's vital specs suggest that it ought to smash the GeForce GTX 1080... but it doesn't, mainly because it's not as effective in utilising its arsenal of cores and caches for gaming purposes.
Navi is more efficient, AMD says, because it has a combination of new compute units, a multi-level cache hierarchy, and a streamlined graphics pipeline. Let's take each in turn.

It's worth taking a look at the high-level block diagram of the Navi 10 design, the one powering both the XT (full implementation) and regular (reduced implementation) GPUs.
Navi 10 has 40 compute units each home to 64 streaming processors (shaders), offering 2,560 in sum. That's some way down on Vega 64 and 56 with their 4,096 and 3,584 processors, respectively, but what's interesting is that each CU in Navi has a second scalar unit - which handles math problems - and second scheduler which combine to offer twice the instruction rate as on previous generations. Why? Because it is more efficient to do so for gaming-type workloads.
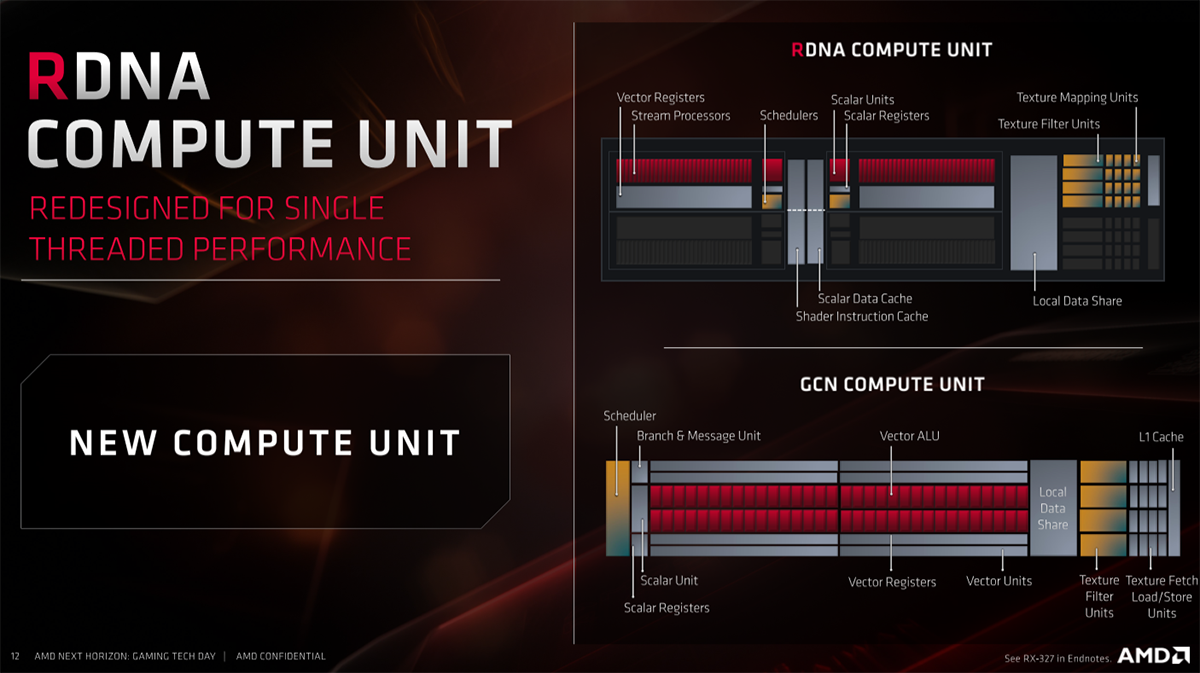
GCN works by having four SIMD16 units - meaning each unit can process 16 elements at one time - but their problem, in terms of latency and utilisation, is that they cannot process an instruction in a single clock cycle. It usually takes four cycles, or four clocks, to run it from start to finish. That's okay if you're doing a four-step calculation such as a fused-multiply-add, yet is not so efficient if the instruction calculation is simpler.
In that case, unless you use some clever pipelining to mask the wasted clocks, the GPU becomes inefficient. What you need to know is that GCN is great for complex instructions often present in the scientific space - it's a fantastic calculator - but not so hot for gaming code unless pipelined very well. And that's the crux of it; GCN needs sufficiently complex work and excellent scheduling if it's to hit its rated throughput specification.

All of this leads to one of RDNA's chief improvements. Rather than use a SIMD16 with a four-clock issue, RDNA uses dual SIMD32s with a single-clock issue, meaning that the compute unit can be kept better utilised for gaming code. Oversimplifying it a lot, RDNA effectively turns the compute-centric GCN architecture into a more gamer code-friendly one. You can run an entire Wavefront32 - the smallest unit of execution, half the width of Wave64 on GCN - on a SIMD32 in one cycle.
The compiler can still pick, on a draw-call basis, whether it wants to execute in Wave32 or Wave64 - the latter across both SIMD32s, based on workload. Aiding extra parallelism, resources from two adjacent CUs can be combined and applied to a larger workgroup, further helping reduce latency.
Better Cache, Lower Latency
The overarching purpose of the change from older GCN to RDNA is to reduce latency, improve single-threaded performance, and enhance cache efficiency. Basically, do more useful work, per CU, per clock cycle, than on GCN. This is why you cannot readily compare a 40CU GCN to a 40CU RDNA unit.
That said, you may wonder why all this focus on single-threaded performance and efficiency when graphics computation is actually a very parallel exercise. The reason is that, although there are tens of thousands of threads in flight, it's not easy keeping a GCN-type machine totally full across a wide range of diverse workloads, and that's the reason for the manifest changes in RDNA.
So, assuming your instructions don't have too many dependencies, having dual scalar and schedule units plus a rearranged SIMD ought to provide more consistent, better performance.

Looking at caching, Radeon takes a leaf from the Ryzen playbook and adds dedicated L1 cache and doubles the load bandwidth from the nearest cache to the ALUs. The purpose here is to reduce the cache access latency at every level, and that means an improvement in effective bandwidth because the requested data remains in caches rather than having to be pulled from slower framebuffer memory.
There are other improvements, too. AMD cites that RDNA improves upon colour compression across the pipeline. In graphics, you compress everything you can, everywhere you can, to reduce utilised bandwidth. RDNA improves the delta colour compression algorithm itself and, now, the shaders can read and write compressed colour data directly. The display portion of the chip can now directly read compressed data stored in the memory subsystem, as well.
Like the CU improvements, the premise is to increase available bandwidth and drive down power compared to the way it is done on GCN.
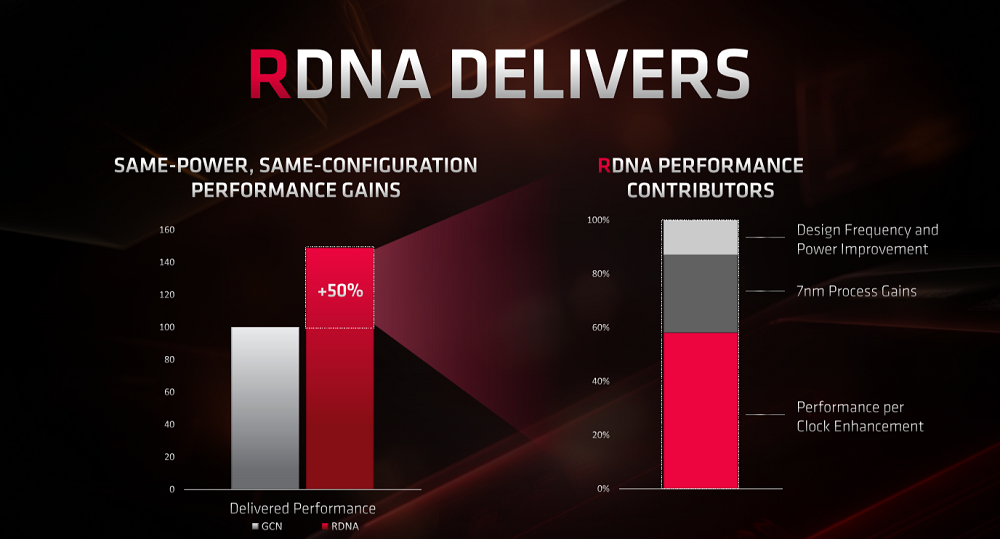
There are a heap of other micro-architecture improvements under the hood, of course, but if we had to sum up RDNA vs. GCN, we'd say that it turns the older, pervasive architecture into a more efficient, gamer-friendly one. The upshot is that comparing the same on-paper TFLOPS throughput and GB/s bandwidth for GCN and RDNA will result in higher framerates for the latter.
Putting some numbers in for context, AMD reckons that, at the same clocks, RDNA offers around 25 per cent extra performance. However, given the 7nm process node and higher frequencies made available through extensive analysis of logic utilisation, RDNA ought to be 50 per cent faster on a CU-to-CU basis.