

A computer scientist in Germany has discovered that some Xerox WorkCentre and ColorQube photocopier machines are substituting numbers willy-nilly, but only when scanning, not photocopying or carrying out any other functions. The most commonly interchangeable numbers were observed to be 6 and 8. The scientist looking into this bug, David Kriesel, also found several other numbers may be substituted in scans but that occurrence is less common. The implications for many users could be serious as carefully measured dimensions, invoices and even medicine doses are scanned and reproduced with errors.

One of the affected machines
Mr Kriesel writes on his blog that the errors are not caused by a problem with the Xerox WorkCentre OCR software; this functionality was switched off during his verification testing. Instead he says the problem is "patches of the pixel data are randomly replaced in a very subtle and dangerous way: The scanned images look correct at first glance, even though numbers may actually be incorrect". Kriesel also confirmed that the number-switching bug is present in the most up-to-date software/firmware scanners.
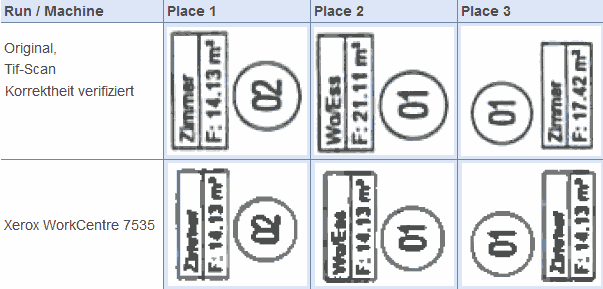
Changes to dimensions on an architectural plan
To observe the error in your own documents and your own Xerox WorkCentre is not very difficult; the settings used by Kriesel show that the Xerox was set to scan 'Photo and text' documents at normal quality and 200dpi using a small data size which would then be saved out to PDF (for later archiving or re-printing, etc). The input document used Arial 7pt and/or 8pt for its letters and numbers. None of these settings would be very unusual for people to use; 200dpi is a standard fax resolution so should be good enough for most document management purposes and the Arial font is very widely used.
Xerox has since commented that character transformation will only occur if two separate settings are altered by the user when performing a scan, and that the character substitution issue is not present when scanning with the factory default settings. Leading on from this, the vast majority of Xerox customers are unlikely to be affected by this issue, the company has said.
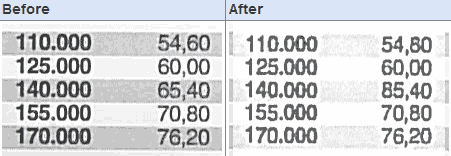
Errors are easily reproduced
Since only files scanned with compression on the Xerox machines exhibit the problem, not OCR PDFs or uncompressed TIFs, Kriesel theorised that the Xerox implementation of the JBIG2 compression algorithm may be swapping out 'similar' blocks of numbers as it does its file-size reduction job. This theory has been since confirmed to be the actual cause in a discussion with Xerox management. JBIG2 compression "creates a dictionary of image patches it finds 'similar'. Those patches then get reused instead of the original image data, as long as the error generated by them is not 'too high'," wrote Kriesel after investigating possible causes. He concluded that Xerox should have chosen a smaller 'patch size' and it appears to be negligent in allowing this overly heavy compression to be enabled without warning.
To fix the problems with these photocopiers Kriesel suggests the following solutions:
- Remove patch based lossy compression from the machines entirely (memory usage is no issue any more), or
- Force the user to click away some notification every single time an PDF is created with this scanning mode, so he nows, everything might happen. Additionally, for later users, add an watermark to the PDF.
Below is a list of Xerox machines which are reported to be affected by the number-jumbling bug.
- WorkCentre 7530
- WorkCentre 7328
- WorkCentre 7346
- WorkCentre 7545
- WorkCentre 7535
- WorkCentre 7556
- Xerox ColorQube 9203
- Xerox ColorQube 9201
- Xerox ColorQube 8700




{kind=link}