

Researchers from Microsoft and the University of Washington have been working on DNA data storage for a number of years now. Back in 2016, HEXUS reported upon the collaborating research partners setting a record for DNA data storage and earlier the same year Microsoft showed some intent by signing a big contract with a synthetic DNA production company. The most recent HEXUS article about DNA storage, from 2017, suggests that DNA is the answer to our ever growing storage needs as up to 215 petabytes of data can be encoded in a single gram of this molecular material. Furthermore, DNA can last much longer than current archival storage technologies.
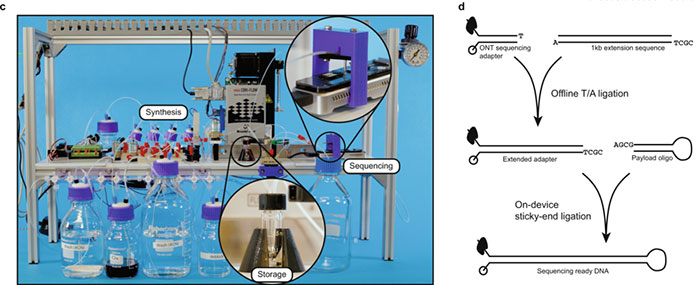
Microsoft and UW provided an update on their progress in the field of DNA storage a couple of days ago, sharing a blog post and video about the world's first fully automated DNA data storage system. The system, pictured below, doesn't look much like any storage device I have seen before but only forms a "simple proof-of-concept test" of the technology working - melding the organic molecular and electronic worlds. Automation is a very important part of any data storage / retrieval system and this is what the above embedded video and accompanying blog concentrates upon.

In the future Microsoft expects DNA to be able to "fit all the information currently stored in a warehouse-sized data centre into a space roughly the size of a few board game dice" but for now its DNA storage and retrieval system looks rather Heath Robinson / Rube Goldberg. However, appearances aren't everything, or even anything, in the world of tech components (you could always add some RGBs if you like). The machinery you see cost about $10,000 in off-the shelf parts.
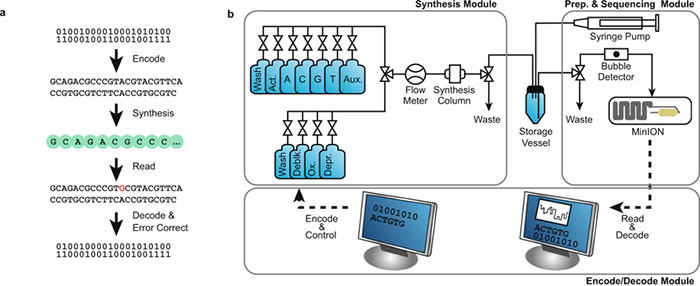
The working system uses software developed by the Microsoft and UW to convert computer data 0s and 1s into As, Ts, Cs and Gs that make up the building blocks of DNA. Then the apparatus flows various liquids and chemicals into a synthesizer that builds manufactured snippets of DNA and pushes them into a storage vessel. To 'read' the data back microfluidic pumps to push the liquids into other parts of the system and from there it is read by sensors and converted back to 0s and 1s. "Having an automated system to do the repetitive work allows those of us working in the lab to take a higher view and begin to assemble new strategies — to essentially innovate much faster," explains Microsoft researcher Bichlien Nguyen.
Storage and retrieval system wasn't built for speed
While the researchers sound very pleased with themselves for designing the automated DNA storage and retrieval system it is currently very slow. In a demonstration of the system, a 5-byte message 'HELLO' (01001000 01000101 01001100 01001100 01001111 in bits) was encoded, stored, and then decoded in 21 hours. This performance is described as "not yet commercially viable," in the full Nature published white paper. However, the researchers say that they are expecting near-term improvements on synthesis, cycle count, and cost. We are asked to remember that "the goal of the project was not to prove how fast or inexpensively the system could work… but simply to demonstrate that automation is possible".
In other related developments, Microsoft researchers have been able to store 1 gigabyte of data in DNA. Furthermore, they have discovered ways to perform meaningful computation "like searching for and retrieving only images that contain an apple or a green bicycle, using the molecules themselves and without having to convert the files back into a digital format".



