

Hewlett Packard Enterprise (HPE) has issued a support bulletin for users of its SAS Solid State Drives. If left unpatched certain models, which were sold individually and as parts of other server and storage products, will fail as they pass 32,768 hours of operation. Understandably this is listed as a critical fix by HPE and users are recommended to apply patches immediately.

If you are running any HPE SAS SSD with drive firmware version older than HPD8 please head on over to the support bulletin page to check for your HPE Model number / SKU to see if it affected by this critical bug. The affected parts list is rather long and includes a number of HPE server and storage products from the ProLiant, Synergy, Apollo, JBOD D3xxx, D6xxx, D8xxx, MSA, StoreVirtual 4335 and StoreVirtual 3200 lines.
Looking more closely at this peculiar bug, it is said to cause "drive failure and data loss at 32,768 hours of operation and require restoration of data from backup in non-fault tolerance, such as RAID 0 and in fault tolerance RAID mode if more drives fail than what is supported by the fault tolerance RAID mode logical drive". The "firmware defect" will make itself known after 32,768 hours of operation, which equates to 3 years, 270 days 8 hours of runtime. HPE adds that if you run one of these storage devices past this duration and it fails "neither the SSD nor the data can be recovered," and compounding the issue for users will be that SSDs put into service in a batch will all likely fail simultaneously.
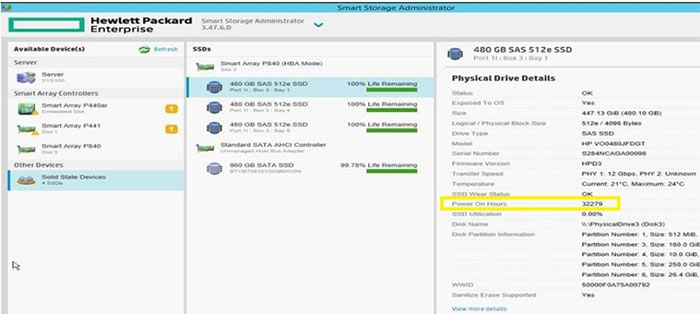
HPE's Offline Smart Storage Administrator software for Windows and Linux can show you your SSD drive power on hours in its GUI. However, it is probably advisable to just head on over to the new firmware download links about two thirds down the HPE support bulletin page to download and apply this firmware if you are anywhere near 3 years of use of your HPE SAS SSD product. Meanwhile, there have recently been reports of HPE SSD failures due to this bug, on Reddit.
Please note that only eight of the 20 drives affected have patches available today. You will have to wait until the second week in December for patch files for the remaining 12 affected SKUs. HPE assures that those waiting for patches couldn't have run their SSDs long enough yet for the critical failure to occur.
While HPE didn't provide any hints about what might be tripping this 'SSD kill switch' at 32,768 hours of operation, some experts have speculated that it could be a permanent crash caused by integer overflow. A quick Google indicates that the maximum signed range of integer values that can be stored in 16-bits is 32,768, which is probably relevant to both the problem and solution.



